Availability Management
Availability Management is required to monitor the health of the service. Performance and Availability thresholds defined in Service Level Agreements (SLAs) and Operational Level Agreements (OLAs) when exceeded may trigger Events. Availability Metrics are utilized to verify compliance with agreed-upon SLAs and OLAs.
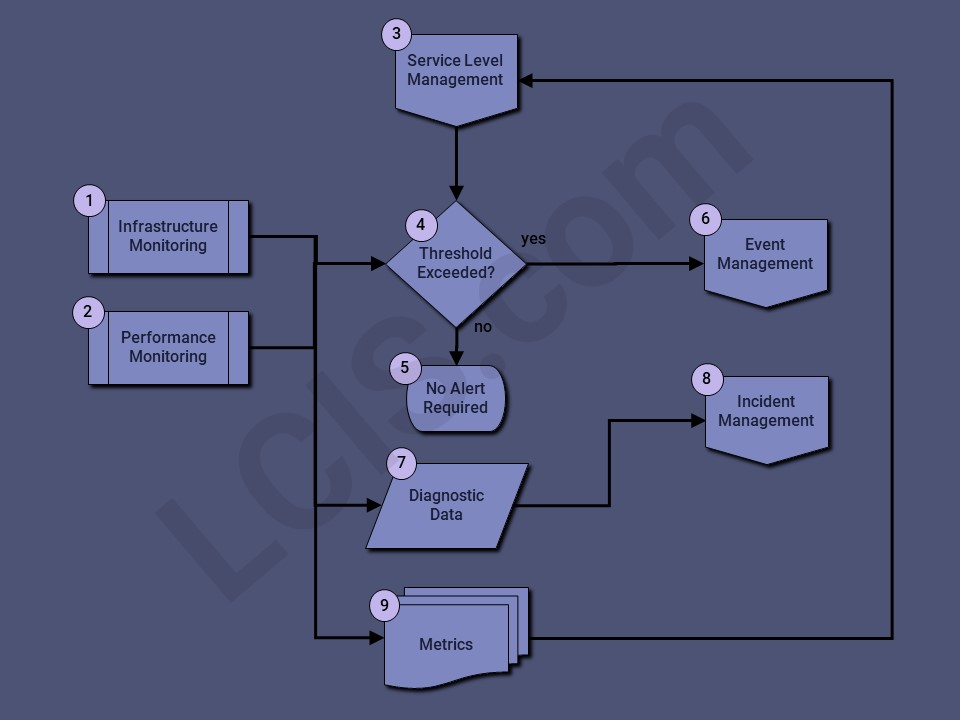
- Infrastructure Monitoring consists of tools that track the real-time health of service components like servers, databases, storage, and networks. For example, a server CPU spiking at 100% for a prolonged period indicates a serious issue likely impacting services hosted on the server, requiring immediate attention.
- Performance Monitoring is often accomplished with synthetic transaction monitoring. This method requires a tool that mimics basic user functions in the service (e.g., log on, perform task, verify task completion, log off), from locations across the globe, at regular intervals (e.g., every 15 minutes). This allows Operations to quickly identify if outages are impacting all users or isolated to specific global regions.
- Service Level Management provides the agreed-upon thresholds when a service becomes unavailable, and/or when the performance is degraded below acceptable levels. These tools are configured so that the Availability of the service is not monitored during agreed-upon maintenance periods.
- If the thresholds defined in the Service Level Agreement determine an alert is required, the Event Management (6) process is initiated
- No alert is required if the threshold is not exceeded.
- Event Management will capture the timing and threshold information to initiate the appropriate response and notifications.
- Diagnostic Data is captured by the tools, including impacted geographic locations.
- Incident Management leverages the Diagnostic Data to troubleshoot and remediate the issue, including timing and other services impacted.
- Metrics of the service Availability can drive the Service Level Management (3) process, including Early Life Support exit criteria.